
BYO-LLM overview
Large language models (LLMs) are game changers in the ever-evolving post-generative artificial intelligence (gen AI) world. They have reshaped our understanding and utilization of AI/ML, transforming how we interact with data, automate processes, and derive insights by easing time-consuming tasks, such as data labeling.
For instance, financial institutions must carefully monitor client-employee interactions, both in text and audio formats, to ensure compliance with regulations and prevent financial and reputational damage. Analyzing these interactions can be a labor-intensive process that requires extensive labeling. That’s where gen AI comes into play, automating the entire process. However, highly regulated institutions often face challenges in adopting such technologies due to the need to vet additional vendors and navigate a complex compliance onboarding process.
This is where Teradata’s Bring Your Own Large Language Model (BYO-LLM) comes in. Teradata understands these needs and has developed the capabilities to implement generative AI that is Trusted AI within its Teradata VantageCloud Lake environments. This allows data scientists, AI specialists, analytics leaders, and data practitioners to fully leverage open source LLMs with the greatest degree of control.
Let’s dive a little deeper into BYO-LLM!
What is BYO-LLM?
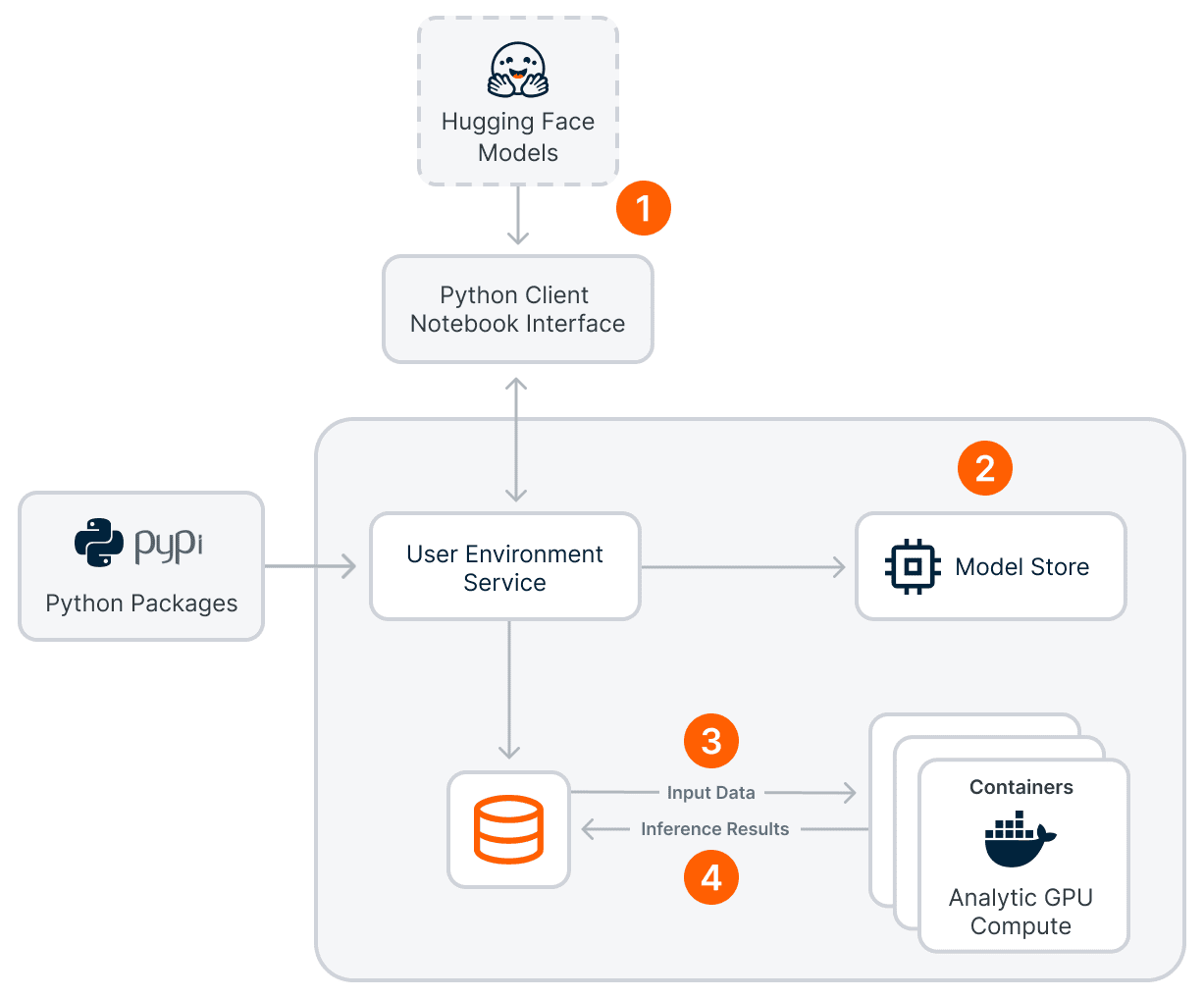
Bring Your Own LLM is a capability of Teradata’s Open Analytics Framework that lets you seamlessly integrate open-source LLMs from popular AI communities like Cohere, Hugging Face, and Meta Llama into VantageCloud Lake and harness the full potential of open-source LLMs.
Open Analytics Framework is a scalable and extensible framework for executing third-party open-source and custom analytics within the analytics compute group of VantageCloud Lake. You can think of Open Analytics Framework as a framework that allows you to create different Python environments with various package versions and requirements for use in your VantageCloud Lake system. And these environments can be GPU powered!
The combination of LLMs and GPU processing significantly boosts performance, leading to a larger impact. To support these capabilities, Teradata has added a new Analytic GPU cluster to the VantageCloud Lake environment, offering both CPU and GPU instances, allowing you to choose the processing power that best meets your requirements.
Currently, BYO-LLM is available with VantageCloud Lake on AWS, with plans to expand to Microsoft Azure and Google Cloud soon.
How does BYO-LLM work with VantageCloud Lake?
Bringing your own LLMs to VantageCloud Lake using the Open Analytics Framework is simple and involves just a few steps.
1. Provision an analytics compute group in your VantageCloud Lake instance
VantageCloud Lake is Teradata’s cloud-native analytics and data platform that provides lakehouse deployment patterns along with the ability to run independent elastic workloads using an object storage-centric design. To effectively implement BYO-LLM, it’s essential to ensure that your VantageCloud Lake system is provisioned with analytics compute group. Depending on the size of the model, you may need to allocate a GPU-powered compute group.
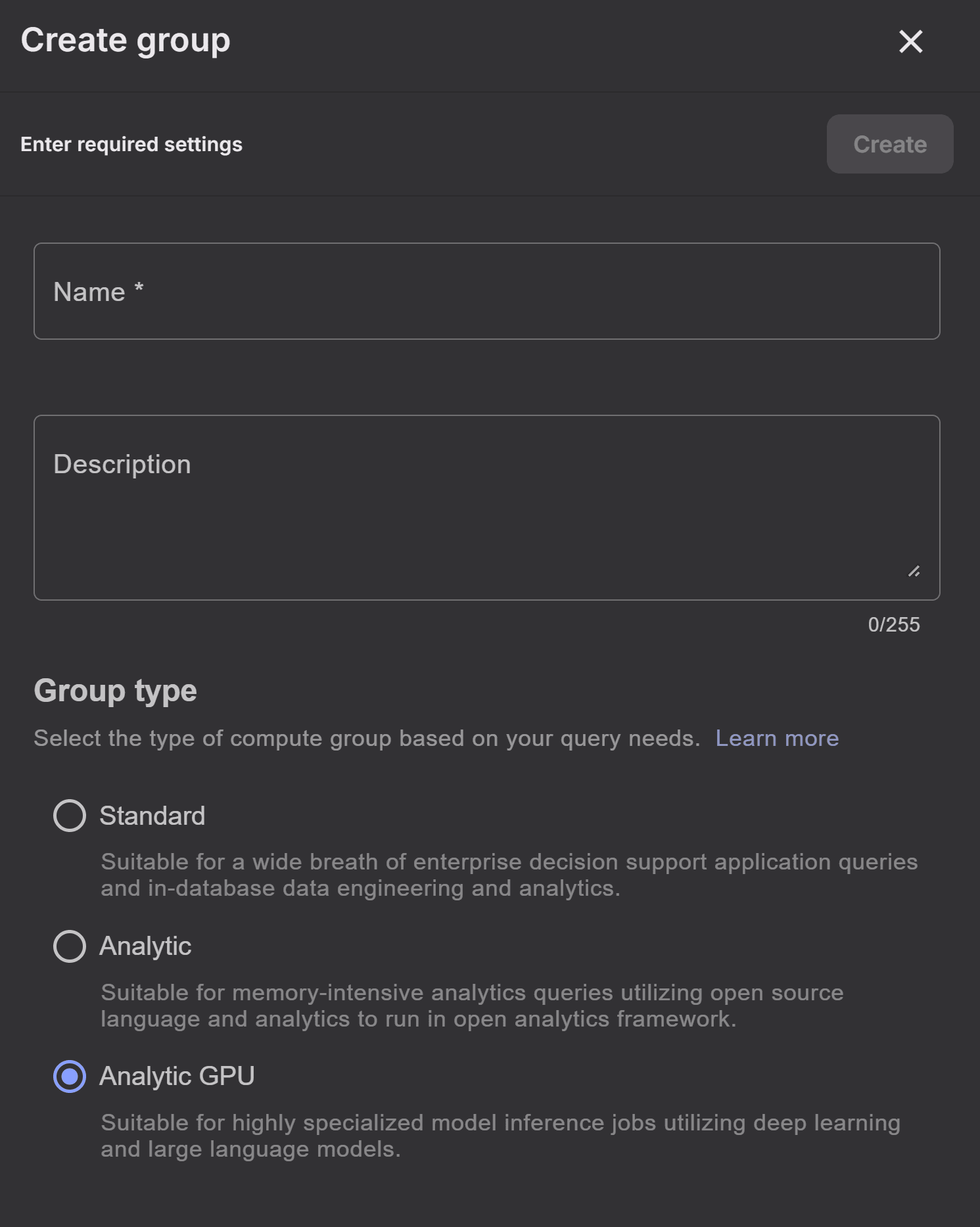
Create an Analytic type of compute group
Additionally, you’ll need your Open Analytics endpoint along with the corresponding connection string, both of which can be conveniently obtained from the VantageCloud Lake dashboard.
2. Install Python packages
To install the necessary Python dependencies, you’ll need to start a JupyterLab environment on your local machine. Teradata provides a convenient Docker image that comes preloaded with all the essential Teradata utilities, making this setup a breeze. You can run this image using various methods, including:
Once your environment is up and running, the required dependencies can be easily imported into a Jupyter Notebook:
from teradataml import *
from teradatasqlalchemy.types import *
import pandas as pd
3. Connect with your VantageCloud Lake environment and check cluster status
Connecting to VantageCloud Lake with Teradata utilities is straightforward. A connection can be established with a single line of code:
eng = check_and_connect(host=host, username=username, password=password, compute_group=compute_group)
After establishing the connection, verify that an analytics cluster is running:
res = check_cluster_start(compute_group = compute_group)

Active compute cluster
This ensures that the environment is fully operational and ready for analytics tasks.
4. Create a user environment
After confirming that the cluster is running, create a user environment with the desired configuration of Python interpreter, utilizing the Open Analytics Framework APIs. The following code snippet demonstrates how to create an Open Analytics Framework user environment:
try:
demo_env = create_env(env_name = oaf_name,
base_env = f'python_{python_version}',
desc = 'OAF Demo env for LLM')
except Exception as e:
if str(e).find('same name already exists') > 0:
print('Environment already exists, obtaining a reference to it')
demo_env = get_env(oaf_name)
pass
elif 'Invalid value for base environment name' in str(e):
print('Unsupported base environment version, using defaults')
demo_env = create_env(env_name = oaf_name,
desc = 'OAF Demo env for LLM')
else:
raise

Selecting an environment
The user environment is crucial for locking down the specific Python and package versions needed for deploying models within the container.
5. Install dependencies in user environment
Next, install the dependencies of your model in the user environment.
# v_pkgs is a list of packages
demo_env.install_lib([x.split('+')[0] for x in v_pkgs], asynchronous=True)
The “install_lib” function installs the required dependencies in the “demo_env”.
Installing dependencies in the environment
6. Download and install pretrained model
Following this, the pretrained model needs to be installed. If necessary, compress the model file or directory into a zip file. For instance, the code snippet below demonstrates how to work with the Sentence Transformer from Hugging Face:
from sentence_transformers import SentenceTransformer
import shutil
print('Creating Model Archive...')
model = SentenceTransformer(model_name)
shutil.make_archive(model_fname,
format='zip',
root_dir=f'{expanduser("~")}/.cache/huggingface/hub/{model_fname}/')
demo_env.install_model(model_path = f'{model_fname}.zip', asynchronous = True)
In this script, the model is downloaded and assigned to the “model_name” variable, creating a zip archive. This zip is then passed to the “install_model” function to install it in the environment.
Installing the pretrained model
Once the installation is complete, the installed model can be verified by running the “demo_env.models” function.

Information of installed model
7. Create and test an embedding function
Next, create a local function to call the Sentence Transformer object. Here’s how this can be done for generating an example embedding from a string of text:

A local function leveraging pretrained model
def create_embeddings(row):
from sentence_transformers import SentenceTransformer
import torch
model = SentenceTransformer('BAAI/bge-small-en-v1.5')
# check for NVIDIA drivers
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# create series from the embeddings list that is returned
s = pd.Series(model.encode(row['text'], device = device))
# concat them together
row = pd.concat([row[['id']], s], axis = 0)
return row
# Testing on local data
df = pd.DataFrame({'id':[1,2], 'text':['hello world', 'hello back']})
df.apply(create_embeddings, axis = 1)

Test result of apply method on local data
8. Push the embedding function to analytic cluster
Next, create a teradataml DataFrame to leverage the VantageCloud Lake cluster’s scalability. This DataFrame resembles a Pandas DataFrame but represents data residing on the server.
df_comments = DataFrame('"demo_ofs"."CFPB_Complaints"')
ipydisplay(tdf_comments.to_pandas(num_rows = 1))

Example of Teradata DataFrame usage presenting comments
Pushing the processing to GPU Analytic cluster
Using the Teradata DataFrame apply function, the code of our `create_embeddings` function can be packaged and sent to the Analytics cluster for execution:
tdf_embedded = tdf.apply(lambda row: create_embeddings(row),
env_name = demo_env,
returns = types_dict)
The output generated by apply function can be further used according to your business use case.
You can watch the complete video below and explore the full demonstration notebook on customer complaint analytics with Teradata BYO-LLM.
Benefits of BYO-LLM
BYO-LLM unlocks numerous benefits associated with open-source LLMs, enhancing operational efficiency and innovation for developers, organizations, and customers. Here are the key advantages of BYO-LLM:
- Seamless integration. BYO-LLM gives developers the ability to deploy open LLMs where the data resides, in the same system environment. This saves time for data scientists.
- Optimized performance. With the addition of a new Analytic GPU cluster in VantageCloud Lake, data scientists can access both CPU and GPU instances and optimize processing power based on their needs.
- Scalable solutions. With VantageCloud Lake's Analytic GPU compute clusters, data engineers and data scientists can easily scale batch inferences and manage varying workloads, ensuring reliability and efficiency.
- Developer-friendly deployment. Data engineers and data scientists can easily deploy LLMs using Teradata’s Python teradataml APIs, while the Open Analytics Framework provides access to PyTorch. Additionally, PyPi and Anaconda users have a choice to access PyTorch and related libraries from two sources.
- End-to-end analytic capabilities. Teradata VantageCloud and ClearScape Analytics™ provide end-to-end analytic capabilities to solve business use cases in a holistic way by linking the power of generative AI with in-database AI/ML capabilities, enabling data scientists to perform all analytical operations in one place.
- Transparent pricing. The pricing model is straightforward, with costs clearly defined at a per-minute rate, ensuring there are no hidden fees or unexpected expenses.
BYO-LLM empowers organizations and developers to harness the benefits of open-source LLMs effectively. It not only removes major pain points but also drives innovation and improves business outcomes while addressing the challenges associated with AI deployment.
BYO-LLM use cases
BYO-LLM is a game changer for developers and organizations looking to tap into the potential of open LLMs. By integrating these models into your VantageCloud Lake environment, you can more effectively overcome the challenges that come with traditional API-based solutions.
There are numerous use cases across various industries and verticals that can benefit from BYO-LLM, including:
- Content generation. Media and marketing companies can more efficiently create articles and marketing materials.
- Customer complaint analysis. Businesses can automate the processing of customer feedback to identify and address complaints quickly.
- Healthcare document processing. Healthcare companies can streamline the analysis of medical notes and patient records.
- Knowledge management. Organizations can improve information retrieval by enabling natural language queries.
- Product recommendations. Businesses can enhance customer experience through personalized product suggestions.
- Regulatory compliance. Finance and healthcare companies can monitor communications for compliance-related issues.
- Sentiment analysis and topic detection. Brands can analyze public sentiment and identify emerging trends.
The advantages of BYO-LLM are significant, and when combined with Teradata’s capabilities in Trusted AI, it enhances security and compliance, making data management more effective and yielding better results.
As generative AI continues to evolve, adopting BYO-LLM positions your organization to transform challenges into exciting opportunities for growth. It’s all about harnessing the flexibility and power of open LLMs to drive meaningful impact and value for your business and customers.
Explore how BYO-LLM can elevate your AI initiatives.